ASCII, Unicode, UTF-8 y la Iñtërnâçiônàlizæçiøn - parte I
Publicado por Juan Pablo el 25.Ene.2006 | Comentarios (23)
 Hace meses que llevo coleccionando enlaces sobre Unicode y UTF-8; dado que en español hay muy poca información me he decidido a publicar mis notas, ordenadas de tal forma que puedan ser digeribles para cualquier persona interesada en el tema. Pero debo hacer una advertencia: habrán pasajes donde nos sumergiremos en las más profundas aguas informáticas, así que no olvides traer un tanque de oxígeno para soportarlo.
Hace meses que llevo coleccionando enlaces sobre Unicode y UTF-8; dado que en español hay muy poca información me he decidido a publicar mis notas, ordenadas de tal forma que puedan ser digeribles para cualquier persona interesada en el tema. Pero debo hacer una advertencia: habrán pasajes donde nos sumergiremos en las más profundas aguas informáticas, así que no olvides traer un tanque de oxígeno para soportarlo.
A modo de prólogo definiremos algunos conceptos, viajaremos en el tiempo, estableceremos problemas y finalmente llegaremos a la genialidad aquella llamada UTF-8, aunque también haremos algunas paradas en códigos y ejemplos para logran una mejor compresión de los conceptos, no hay duda ¡nos divertiremos como locos!.
Introducción
Veamos algunas definiciones:
- Un caracter es el componente más pequeño de un lenguaje escrito y además posee un valor semántico. Ejemplos de caracter: “1”, “.”, “A” “纯”.
- Un conjunto de caracteres es un grupo de caracteres sin ningún valor numérico asociado. Ejemplos de conjunto de caracteres puede ser el alfabeto Español o el Cirílico (usado en Rusia y Bulgaria).
- Un conjunto de caracteres codificados es un grupo de caracteres asociados a un valor escalar. Ejemplo la letra “A” mayúscula, que según la tabla ASCII tiene el valor 65.
Manten estas definiciones en tu mente.
 Todo el mundo sabrá que un computador funciona en base a cambios eléctricos: prendido y apagado, sí y no; un estado binario que es representado con 1's y 0's respectivamente, absolutamente todo es representado en ceros y unos dentro de estas maquinitas: un mp3, una fotografía digital, un texto, etcétera. Quedemos con el texto por un momento; cuando escribimos uno igualmente queda almacenado en el computador como una hilera de 0's y 1's. Supongamos que escribimos un texto con la palabra: Hola, su representación binaria sería:
Todo el mundo sabrá que un computador funciona en base a cambios eléctricos: prendido y apagado, sí y no; un estado binario que es representado con 1's y 0's respectivamente, absolutamente todo es representado en ceros y unos dentro de estas maquinitas: un mp3, una fotografía digital, un texto, etcétera. Quedemos con el texto por un momento; cuando escribimos uno igualmente queda almacenado en el computador como una hilera de 0's y 1's. Supongamos que escribimos un texto con la palabra: Hola, su representación binaria sería:
Binario Caracter ------------------ 1001000 | H 1101111 | o 1101100 | l 1100001 | a
¡Esperen un momento!, ¿cómo es que el binario 1001000 representa el caracter “H”?, ¿perfectamente pudo haber sido el 1110011?, ¿cómo puedo creer lo que me dices?, ¿en qué te basas?. Son preguntas muy válidas (creo que estoy comenzando a capturar tu atención ¿he?) cómo dijo Jack, vamos por partes.
Viajando al pasado
 El mundo de la informática —querámoslo o no— tuvo su origen en Los Estados Unidos, allá por 1963 era necesario establecer un estándar para el intercambio de información, es así como se creó el conocido código ASCII (aunque también es conocido como US-ASCII), el cual define un conjunto de caracteres asociados a un valor escalar, según esta tabla el caracter “H” se representará como 1001000; ¿ahora me crees?, espero que sí. “¡Fantástico!, ya tenemos un estándar para el intercambio de información para nuestro idioma” —decían los patriarcas de la informática, nótese “para nuestro idioma”. Correcto, el estándar ASCII definía un conjunto de caracteres sólo para el habla inglesa, es decir, su alfabeto (que por lo demás es bastante simple), números, signos de puntuación, caracteres de control. La suma total de caracteres va desde 0 al 127, en total 128 (27) divididos en 4 grupos.
El mundo de la informática —querámoslo o no— tuvo su origen en Los Estados Unidos, allá por 1963 era necesario establecer un estándar para el intercambio de información, es así como se creó el conocido código ASCII (aunque también es conocido como US-ASCII), el cual define un conjunto de caracteres asociados a un valor escalar, según esta tabla el caracter “H” se representará como 1001000; ¿ahora me crees?, espero que sí. “¡Fantástico!, ya tenemos un estándar para el intercambio de información para nuestro idioma” —decían los patriarcas de la informática, nótese “para nuestro idioma”. Correcto, el estándar ASCII definía un conjunto de caracteres sólo para el habla inglesa, es decir, su alfabeto (que por lo demás es bastante simple), números, signos de puntuación, caracteres de control. La suma total de caracteres va desde 0 al 127, en total 128 (27) divididos en 4 grupos.
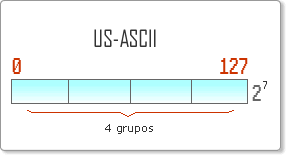
Tabla US-ASCII
* | 0 1 2 3 4 5 6 7 8 9 A B C D E F
--------------------------------------------------------------
0 | NUL SOH STX ETX EOT ENQ ACK BEL BS TAB LF VT FF CR SO SI
1 | DLE DC1 DC2 DC3 DC4 NAK SYN ETB CAN EM SUB ESC FS GS RS US
2 | (1) ! " # $ % & ' ( ) * + , - . /
3 | 0 1 2 3 4 5 6 7 8 9 : ; < = > ?
4 | @ A B C D E F G H I J K L M N O
5 | P Q R S T U V W X Y Z [ \ ] ^ _
6 | ` a b c d e f g h i j k l m n o
7 | p q r s t u v w x y z { | } ~ DEL
(1): caracter de espacio
Por comodidad y convención de ahora en adelante ya no nos vamos a referir a nuestro caracter “H” con su representación binaria, ahora nos referiremos a él en su notación ASCII hexadecimal, es decir 0x48 (fila 4, columna 8 de la tabla). El intervalo 0x00 a 0x1F son abreviaturas en inglés de: nulo, comienzo de cabecera, comienzo de texto, fin de texto...etc. Este grupo también es llamado no imprimible dado que todos son caracteres de control. Curiosidad: el caracter ASCII 0x7 por ejemplo es el caracter que hace que nuestro computador haga “bip”. La tabla completa, junto con otros interesante datos puedes verla en wikipedia.
 Una de las primeras cosas que nos enseñan en la Universidad sobre informática es eso de los bites y bytes. Un bit es un dígito en el sistema de numeración con base dos, ¡correcto! el código binario. El dos (2) binario se representa con dos bits 10, el cuatro (4) binario con tres 100. Se denomina nibble a un grupo de 4 bits, con cuatro bits podemos representar hasta 24 = 16 valores diferentes, un grupo de 8 bits se denomina octeto y se pueden representar hasta 28 = 256 valores distintos. Un octeto es siempre fijo (8 bits), mientras que un byte es un grupo de 8 bits también pero no siempre ha sido así, cuando la informática estaba en pañales un byte podía contener 6,7,8 o 9 bits. Pero estamos hablando de la prehistoria, hoy en día para la inmensa mayoría de los sistemas un grupo de 8 bits es denominado como un byte. El concepto que debes retener es: que un byte es la unidad básica de almacenamiento de información. Muy bien, luego de tener claro el concepto de bit y byte volvamos a nuestro código ASCII porque de eso estamos hablando ¿o ya lo habías olvidado?.
Una de las primeras cosas que nos enseñan en la Universidad sobre informática es eso de los bites y bytes. Un bit es un dígito en el sistema de numeración con base dos, ¡correcto! el código binario. El dos (2) binario se representa con dos bits 10, el cuatro (4) binario con tres 100. Se denomina nibble a un grupo de 4 bits, con cuatro bits podemos representar hasta 24 = 16 valores diferentes, un grupo de 8 bits se denomina octeto y se pueden representar hasta 28 = 256 valores distintos. Un octeto es siempre fijo (8 bits), mientras que un byte es un grupo de 8 bits también pero no siempre ha sido así, cuando la informática estaba en pañales un byte podía contener 6,7,8 o 9 bits. Pero estamos hablando de la prehistoria, hoy en día para la inmensa mayoría de los sistemas un grupo de 8 bits es denominado como un byte. El concepto que debes retener es: que un byte es la unidad básica de almacenamiento de información. Muy bien, luego de tener claro el concepto de bit y byte volvamos a nuestro código ASCII porque de eso estamos hablando ¿o ya lo habías olvidado?.
Los creadores del ASCII decidieron utilizar 7 bits para almacenar sus caracteres, 27 = 128; todo era perfecto, asumiendo que tú eras un hablante inglés. Pero sobraba un bit para completar el byte, aquel bit se utilizó como bit de paridad y así detectar errores de transmisión. A poco andar muchos comenzaron a pensar que ese bit de paridad podría ser usado para ampliar la gama de caracteres, si sacamos cuentas 28 = 128×2 = 256 caracteres distintos, ¡vaya vaya!. Y he aquí donde comienzan los problemas (voy por un café).
Nuestro inicial ASCII comienza a crecer y a deformarse
 La irrupción en el mercado de los IBM-PC ¿los recuerdas?, trajo consigo la necesidad de ampliar nuestro conjunto de caracteres ASCII, dado que las maquinitas estas invadirían al mundo y no todo el mundo hablaba Inglés, ¿cómo le explicas a un Chileno de la época que no puede escribir “Ñandú” (ni la Ñ ni la ú son US-ASCII) en su planilla de cálculo Lotus 123, “uhhhhhh que software tan viejo” dirán algunos [intimidad] yo aprendí a usar planillas de cálculo con Lotus 1-2-3, por favor ahórrate los comentarios[/intimidad]. Las partidas internacionales de los IBM-PC traían un conjunto de caracteres OEM, es decir, configurado de fábrica, dependiendo de la región del mundo donde iban; todo esto para que el cliente pudiese escribir “Ñandú” sin problemas. Ahora teníamos un ASCII ampliado a 28 caracteres distintos y adaptado a muchos lenguajes alrededor del mundo, desde el 0 al 127 el ASCII original se mantiene intacto, pero desde el 128 al 255 dependerá del conjunto de caracteres que tenga instalado el PC. ¡Todo es perfecto! pero....
La irrupción en el mercado de los IBM-PC ¿los recuerdas?, trajo consigo la necesidad de ampliar nuestro conjunto de caracteres ASCII, dado que las maquinitas estas invadirían al mundo y no todo el mundo hablaba Inglés, ¿cómo le explicas a un Chileno de la época que no puede escribir “Ñandú” (ni la Ñ ni la ú son US-ASCII) en su planilla de cálculo Lotus 123, “uhhhhhh que software tan viejo” dirán algunos [intimidad] yo aprendí a usar planillas de cálculo con Lotus 1-2-3, por favor ahórrate los comentarios[/intimidad]. Las partidas internacionales de los IBM-PC traían un conjunto de caracteres OEM, es decir, configurado de fábrica, dependiendo de la región del mundo donde iban; todo esto para que el cliente pudiese escribir “Ñandú” sin problemas. Ahora teníamos un ASCII ampliado a 28 caracteres distintos y adaptado a muchos lenguajes alrededor del mundo, desde el 0 al 127 el ASCII original se mantiene intacto, pero desde el 128 al 255 dependerá del conjunto de caracteres que tenga instalado el PC. ¡Todo es perfecto! pero....

¡Ha llegado Carta!
Una mañana de marzo de 1995, mi primo Aristóteles Platón Aqueveque me envía un tutorial de cocina griega. Me lo envía desde Atenas en un disquete y vía correo ordinario ¿te acuerdas que la gente antes se comunicaba por cartas?. Yo me fui de inmediato a mi súper computador 386, cargué el Wordstar y ¡plop!, no entendía nada...sólo eran garabatos, un conjunto de caracteres ininteligibles; yo hablo griego de corrido pero no entendí nada. NOTA: Es sólo un ejemplo, con suerte hablo bien Español.
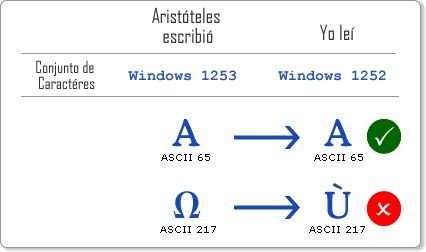
 Donde mi primo escribió una “A” yo leí una “A” (que corresponde al ASCII 65 que es menor a 127), pero donde mi primo escribió una “Ω” (letra griega mayúscula omega que corresponde al ASCII 217 mayor a 127) yo leí “Ù” (letra mayúscula latina U con acento grave). ¿Por qué ocurrió esto?, porque mi primo usa en su computador un sistema de codificación (familia del ASCII) llamado Windows 1253 y yo uso otro llamado Windows 1252, ¿comienzas a percibir el problema?. Por supuesto existen muchos otros sistemas de codificación, todos ellos parientes de nuestro ASCII inicial. No lo olvides, los primeros 127 caracteres no han cambiado para ninguna familia de códigos ASCII, ellos se mantienen intactos (sí, lo repito para que quede bien claro). Habían tantos sistemas de codificación como idiomas, todo esto no sería un gran problema en sistemas cerrados, donde no hay intercambio entre idiomas, pero nadie pensó en el nacimiento de la Red de Redes (Internet), donde sí se produce un gran intercambio de información, es definitivo señores... ¡tenemos serios problemas!.
Donde mi primo escribió una “A” yo leí una “A” (que corresponde al ASCII 65 que es menor a 127), pero donde mi primo escribió una “Ω” (letra griega mayúscula omega que corresponde al ASCII 217 mayor a 127) yo leí “Ù” (letra mayúscula latina U con acento grave). ¿Por qué ocurrió esto?, porque mi primo usa en su computador un sistema de codificación (familia del ASCII) llamado Windows 1253 y yo uso otro llamado Windows 1252, ¿comienzas a percibir el problema?. Por supuesto existen muchos otros sistemas de codificación, todos ellos parientes de nuestro ASCII inicial. No lo olvides, los primeros 127 caracteres no han cambiado para ninguna familia de códigos ASCII, ellos se mantienen intactos (sí, lo repito para que quede bien claro). Habían tantos sistemas de codificación como idiomas, todo esto no sería un gran problema en sistemas cerrados, donde no hay intercambio entre idiomas, pero nadie pensó en el nacimiento de la Red de Redes (Internet), donde sí se produce un gran intercambio de información, es definitivo señores... ¡tenemos serios problemas!.
Basta de caos, ¡un sistema universal por favor!
 Por supuesto que podemos tener todos los sistemas de codificación que necesitemos instalados en nuestros sistemas, para así asegurar el correcto intercambio de información, pero no es una solución práctica. Era necesario un sistema universal y es aquí donde hace su aparición Unicode. Ponte cómodo y deja mirar quién está en línea en tu mensajero instantáneo.
Por supuesto que podemos tener todos los sistemas de codificación que necesitemos instalados en nuestros sistemas, para así asegurar el correcto intercambio de información, pero no es una solución práctica. Era necesario un sistema universal y es aquí donde hace su aparición Unicode. Ponte cómodo y deja mirar quién está en línea en tu mensajero instantáneo.
De forma paralela —a finales de 1980— dos organismos estaban desarrollando un código de caracteres unificado. Una era el “Projecto ISO 10646” de la Organización Internacional para la Estandarización y la otra era el “Proyecto Unicode” organizado por un consorcio de fabricantes de softwares (mayoritariamente de Estados Unidos). ¡Qué paradoja!, dos proyectos distintos desarrollando un estándar universal; la buena noticia es que se dieron cuenta de aquello y decidieron unir fuerzas y trabajar juntos. Ambos organismos (anda a saber tu por qué) decidieron hacer sus publicaciones por separado, pero esto no quiere decir que sigan trabajando estrechamente para futuras extensiones. La relación es esta:
- El Unicode 1.1 es al ISO 10646-1:1993
- El Unicode 3.0 corresponde al 10646-1:2000
- El Unicode 3.2 es el ISO 10646-2:2001
- El Unicode 4.0 es el ISO 10646:2003
Unicode e ISO: una tierna historia ¿pero cuál es la gracia?
 Pero ¿qué es lo que crearon los astutos chicos de Unicode?. Veamos: el caracter “A” en Verdana es igual al caracter “A” en New Roman, pero estos dos son distintos al caracter “a” en cualquiera de los dos tipos de fuentes. Nada nuevo bajo el sol, pero que opinas del caracter alemán “ß”, cualquiera podría pensar que es como hacer una rebuscada “B”, pero no es así, recuerda que cada caracter tiene un significado semántico. Pues bien, esto lo sabían muy bien los chicos de Unicode y la solución era esta: cada caracter será asociado a un valor escalar único e irrepetible, tanto la “A” como la “a” y “ß”; tiene un número asociado : U+xxxx, la U es Unicode y las xxxx un hexadecimal, este número es definido como punto de código (code point).
Pero ¿qué es lo que crearon los astutos chicos de Unicode?. Veamos: el caracter “A” en Verdana es igual al caracter “A” en New Roman, pero estos dos son distintos al caracter “a” en cualquiera de los dos tipos de fuentes. Nada nuevo bajo el sol, pero que opinas del caracter alemán “ß”, cualquiera podría pensar que es como hacer una rebuscada “B”, pero no es así, recuerda que cada caracter tiene un significado semántico. Pues bien, esto lo sabían muy bien los chicos de Unicode y la solución era esta: cada caracter será asociado a un valor escalar único e irrepetible, tanto la “A” como la “a” y “ß”; tiene un número asociado : U+xxxx, la U es Unicode y las xxxx un hexadecimal, este número es definido como punto de código (code point).
Caracter Unicode A U+0041 a U+0061 ß U+00DF
¡Esto está mejorando!, ya tenemos un estándar universar para la representación de caracteres, da lo mismo si recibo correspondencia electrónica de mis primos en Rusia, Mongolia, Iran, Japón o China, como todos usamos Unicode no existirá problemas. No tan rápido kimosabi.
¿De izquierda a derecha o de derecha a izquierda?
No hemos hablado de la forma en que se almacena en memoria o en disco un Unicode, volvamos a nuestro ejemplo inicial (ese de allá arriba, ¿tanto he escrito?, wow), El Unicode de Hola sería:
H o l a U+0048 U+006F U+006C U+0061
El cual, según tu (y yo también) se almacenaría como:
00 48 00 6F 00 6C 00 61
¿Y por qué no puede ser almacenado así también?:
48 00 6F 00 6C 00 61 00
Fue la pregunta que también se hicieron muchos desarrolladores de la época, además que muchos de ellos quería almacenar sus puntos de código en modo high-endian o low-endian, ¡espera!, ¿qué es esto de high y low endian?; bueno, en palabras simples es la forma en que el procesador de un computador lee la información; de izquierda a derecha o de derecha a izquierda (técnicamente hablando son las zonas de memoria, que van desde la más alta a la más baja). Las arquitecturas x86 de Intel y los procesadores Alpha de DEC usan low-endian, mientras que las plataformas Sun's SPARC, Motorola, e IBM PowerPC utilizan la convención big-endian.
 Volviendo a nuestro asunto, el problema que se suscitó es que teníamos dos formas de almacenar Unicode, para solucionar ese problema se definió una muy extraña convención: se le agregaría un FE FF al inicio de cada Unicode. A esto se le llamó Marca de Orden Unicode para big-endian se intercambiaba el orden a FF FE. Uff, es un poco complicado pero soportable. Otro aspecto que no agradaba mucho al los desarrolladores de la época eran esos ceros que no tenían mucho sentido, recuerda que el espacio de almacenamiento en ese tiempo era importante. Además, había que convertir todos los documentos o sistemas que estaban en el antiguo ASCII. El asunto es que todos estos inconvenientes desmotivaron la adopción de Unicode. Todo el desarrollo del estándar quedaría truncado. ¿Y ahora?, ¿quién podrá defendernos?, exacto → UTF-8.
Volviendo a nuestro asunto, el problema que se suscitó es que teníamos dos formas de almacenar Unicode, para solucionar ese problema se definió una muy extraña convención: se le agregaría un FE FF al inicio de cada Unicode. A esto se le llamó Marca de Orden Unicode para big-endian se intercambiaba el orden a FF FE. Uff, es un poco complicado pero soportable. Otro aspecto que no agradaba mucho al los desarrolladores de la época eran esos ceros que no tenían mucho sentido, recuerda que el espacio de almacenamiento en ese tiempo era importante. Además, había que convertir todos los documentos o sistemas que estaban en el antiguo ASCII. El asunto es que todos estos inconvenientes desmotivaron la adopción de Unicode. Todo el desarrollo del estándar quedaría truncado. ¿Y ahora?, ¿quién podrá defendernos?, exacto → UTF-8.
Muy bien, para masticar tanto concepto e historias me quedaré aquí. No se pierdan la parte II y final de este artículo.
Nota: Todo el material publicado en este weblog —a menos que se exprese lo contrario— tiene algunos derechos reservados, no lo olvides por favor. Se respetuso de las reglas del juego y ganarás una buena reputación.
Actualización: Segunda parte ASCII, Unicode, UTF-8 y la Iñtërnâçiônàlizæçiøn - parte II
Referencias usadas para este artículo:
- UTF-8 y Unicode FAQ para Unix/Linux
- Lo que absolutamente cualquier desarrolladorde Softwares debe saber sobre Unicode y Conjunto de Caracteres - no hay excusas
- Entendiendo el Unicode
- Una pequeña historia de los Códigos de Caracteres
Enlace Permanente, Comentarios (23), Publicada en: Estándares
TrackBack
Weblogs que han referenciado la ASCII, Unicode, UTF-8 y la Iñtërnâçiônàlizæçiøn - parte I:
» ASCII, Unicode, UTF-8 y la internacionalización de Garbage In, Garbage Out
... Explica la historia de los sistemas de codificación de caracteres y cómo funciona el UTF-8. Aquí tenéis las dos partes:
ASCII... [continuar leyendo]
Comentarios
- 1. aguayoki
- 26.Ene.2006
Epa, estimado Juque, justamente hace un tiempo había estado revisando material afín... Para decidir si quedarme con el iso-8859-1 o el utf-8. Bueno, aún no lo sé, y sigo haciendo webs con uno u otro estándar. Espero decidirme en la segunda parte...
Buen artículo, de todas maneras. Pero [comentario geek] hay una falla:
habrán pasajes donde nos sumergiremos en las más profundas aguas informáticas, así que no olvides trear un tanque de oxígeno para soportarlo.
Técnicamente, si son aguas profundas, el oxígeno no sirve, puesto que se vuelve tóxico a los 7-10 metros bajo el nivel del mar. Es por eso que el buceo común y silvestre se realiza con aire comprimido... Lo que permite llegar a -30 ó -40 metros.
Y para más profundidad, pues comenzamos con las mezclas... Nitrox, etc. [/comentario geek]
Eso... Saludos, y a la espera de la segunda parte.
- 2. Pollo
- 26.Ene.2006
Pucha, dejas la historia en la mejor parte. Sin embargo, Muchas Gracias por compartirla.
- 3. Pablo Noel
- 26.Ene.2006
articulaso que te mandaste!, personalmente ocupo el iso latin 1 (iso-8859-1) para paginas en español 100%, y utf-8 para sitios en otros idiomas o bilingues.
- 4. RoQ
- 26.Ene.2006
Gracias por el artículo, lo leeré por partes y con calma
- 6. juque
- 26.Ene.2006
Amigos: parece que el artículo gustó, pues eso me alegra. Para la segunda parte pretendo atacar a fondo UTF-8, sería interesante que expusieran sus dudas en esta Entrada para discutirlas en la próxima parte y final de la historia :).
#1: vaya vaya eduardo, eso no estaba en mis libros. Al parecer tenemos un experto en buceo en la sala :), lo tendré presente para cuando vaya a concepción :P, siempre he querido aprender.
#2: Esa era la idea, dejarte con la bala pasada, ¡soy malo verdad!:P
#3: Error pablo, debes usar UTF-8, en la siguiente entrega te darás cuenta. Pero comienza desde ya a migrar todos tus contenidos a UTF-8
#4: De nada. Creo que me pasé de revoluciones, me salió un poco extenso, pero no podía comprimido más
#5: Gracias, sí.. me pasé un par de horas investigando, espero que la segunda parte salga igual de interesante.
- 8. judas
- 26.Ene.2006
muy buen articulo, me gusto. :-)
nosotros ya adoptamos UTF-8 oficialmente en nuestros proyectos,hace un par de meses.
- 9. Nelson Rodríguez-Peña
- 27.Ene.2006
Muy bien Juque, gracias. Para complementar, esto es interesante: en http://ian-albert.com/misc/unichart.php puedes encontrar una gigantesca tabla con el set completo de caracteres UNICODE.
- 12. Hector
- 1.Feb.2006
Enhorabuena, muy buen articulo. Esperando con ansias la 2ª parte.
Felicidades.
- 13. Álvaro Ramírez
- 2.Feb.2006
Muy buena guía, didáctica y entretenida a pesar de los tecnicismos. Yo uso el UTF-8 y sinembargo hay partes de mi blog donde muestra errores con las tildes. No he podido descubrir por qué. Cuál puede ser la razón?
- 14. Djd
- 2.Feb.2006
Muy buen artículo....felicitaciones! Ya se está haciendo popular http://meneame.net/story.php?id=4670
- 15. Huinca
- 2.Feb.2006
Hermoso artículo, hace meses quería leer algo en buen chileno acerca de lo que es UTF-8, i18n y yerbas afines. Y aunque como publicista lo haces genial, las monedas tienen dos caras (las que no son de Moebius, claro). Personalmente uso UTF-8 para trabajar entre Linux, Windows y algunos otros S.O., pero casi siempre me topo con problemas con los editores usuales. Incluso el PuTTY tiene ciertas incoherenciasde dependiendo del sistema. Hay que tener cuidado con eso, y configurar correctamente tu editor. Puede ser tedioso, lo advierto. También, no es raro que algunos servidores sobrescriban los HEADERS y te envíen el contenido en ISO pese a lo que informes en los de tus páginas. Y lo otro, es cuando un tercero edita tus archivos y lo guarda mal en ISO, dejando la escoba con los acentos y eñes.
Son varios detalles con los que hay que lidiar cuando uno se pasa a UTF-8. Lo más seguro es mantenerse bajo el ASCII 128 y usar entidades HTML cada vez que se pueda ( ñ = ñ ).
Ah, y sean precavidos con esto de la internacionalización, no como el bueno de Raulito :)
- 16. juque
- 2.Feb.2006
#13 Alvaro: Aquellas partes de tu blog donde muestra errores es porque aquellos textos están escritos en otro sistema de codificación, imagino que puede ser iso-8859-1. Usando el Notepad de Windows puedes "guardar como" UTF-8. En la segunda parte de esta saga veremos esos problemas y sus soluciones más a fondo.
#14 Djb: Sí, ayer me di cuenta, gracias :).
#15 Huinca: Es importante lo que se señalas, no todo es color de rosa cuando te pasas a UTF-8, pero confío en que con el paso del tiempo todo el mundo —y nuestras aplicaciones también— hablen en UTF-8. Aunque no estoy de acuerdo contigo en sugerir que estoy vendiendo un producto, lo que yo hago es fomentar el uso de un estándar, que tenga bemoles no lo pongo en duda; pero hasta ahora no había ningún sitio en español que hablara al respecto, con tanto ruido que está generando mi artículo creo que estoy logrando mi cometido.
- 17. judas
- 2.Feb.2006
juque: 100% con tu ultimo comentario. Con respecto a los problemas que ocurren cuando se comienza a utilizar UTF-8 si, es cierto que es un poco molesto, sobre todo cuando huinca trata de arreglar los problemas a alto nivel, cuando el problema esta a bajo nivel :-) jejejej.
Con repecto a que otros editen el archivo en ISO y te dejen la escoba, subversion tiene un metodo para defenderse de eso, a traves de un pre-commit hook deniegas que envien archivos que no esten en UTF-8 con un mensaje cliente.
Con respecto a los servidores desconfigurados esta tan simple como agregar un htaccess.
AddDefaultCharset utf-8
para quienes administren servidores aqui, recuerden que su servidor no debe mandar un charset predefinido
AddDefaultCharset Off
en PHP la directiva
default_charset tambien deberia estar en blanco.
PHP6 ( en desarrollo pero funcional en este momento) incluye un soporte completo para unicode, y la gran parte de la funciones lo entienden, aunque demorará mas o menos 1 año mas creo en ver la luz.
Si les interesa saber que mas hay de nuevo en php6 ( mas bien dicho cuanto codigo les va a dejar de funcionar :-) ... lean este articulo
http://www.corephp.co.uk/archives/19-Prepare-for-PHP-6.html
- 19. luistar15
- 13.Feb.2006
Hace como medio año que decidí estandirizar mis sitios... me hubiese agradado encontrar este artículo en aquel entonces, creo que es un gran resumen de lo que encontré... Pero, en el camino de migrar a UTF-8 tuve un gran problema UTF-8 con BOOM y UTF-8 sin BOOM cuando uso un editor de texto (notepad 3.3 a +) y algunos otros tienen la opcion de elegir el tipo de formato en el que guardar... pero cuando genero contenido dinánicamente siempre se generan en ANSI (al menos es lo que me dece el editor)... y es hasta el momento lo único que me está dando líos
así que para la segunda parte sugiero se toquen: UTF-8 con/sin BOOM ANSI ???
:D
- 20. Leo
- 13.Feb.2006
Hace como medio año que decidí estandarizar mis sitios... me hubiese agradado encontrar este artículo en aquel entonces, creo que es un gran resumen de lo que con sacrificio (dada mi limitación del inglés) encontré... Pero, en el camino de migrar a UTF-8 tuve un gran problema UTF-8 con BOOM y UTF-8 sin BOOM cuando uso un editor de texto (notepad++ 3.3 ->) y algunos otros tienen la opcion de elegir el tipo de formato en el que guardar... pero cuando genero contenido dinánicamente siempre se generan en ANSI (al menos es lo que me dece el editor)... y es hasta el momento lo único que me está dando líos
así que para la segunda parte sugiero se traten: UTF-8 con/sin BOOM ANSI ??? xD
:D
- 21. Alex
- 16.Feb.2006
¿Soy el único que está impaciente por leer la segunda parte? ¿Va a tardar mucho en publicarse?